Imagine an organization spending millions on a cutting-edge data science model that demonstrably outperforms existing systems yet business leaders refuse to use it. This is not a hypothetical failure. It is exactly what happened in one of the two case studies analyzed by researchers Paul Brous and Marijn Janssen in their landmark 2020 study published in Administrative Sciences.
The problem is not new. Organizations worldwide are investing heavily in data science to support decision-making, from predicting when a highway needs repair to detecting electricity fraud without violating privacy. Yet again and again, decision-makers hesitate to act on the outputs of these models. Why? Because they do not trust the data. They worry about data quality, about whether the algorithm complies with regulations, and about whether the numbers truly reflect reality (van den Broek & van Veenstra, 2018). In asset management where delaying bridge maintenance can risk public safety and premature repairs waste enormous sums the stakes could not be higher (Brous et al., 2017).
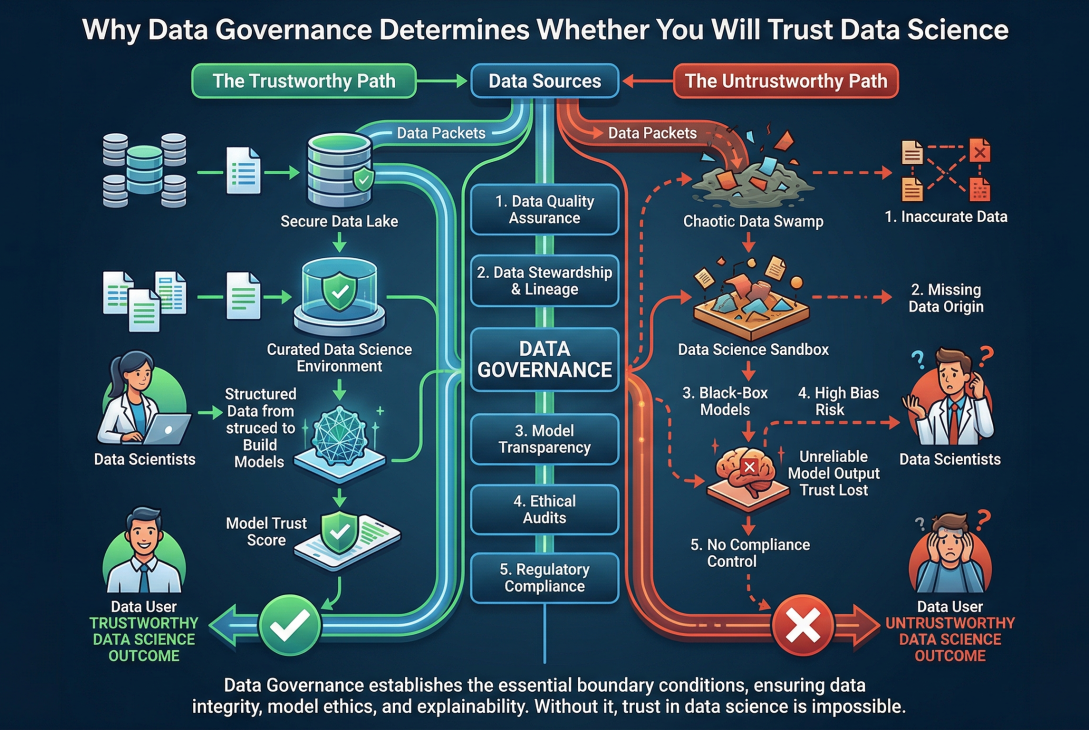
This is where data governance enters the picture. Data governance is not just a technical checklist. It is the exercise of authority and control over the entire lifecycle of data assets: planning, monitoring, and enforcement (DAMA International, 2017). Over the past few years, many organizations have turned to data governance as a way to build trust in their data science initiatives (Al-Ruithe et al., 2019). But until Brous and Janssen’s research, it was not entirely clear how data governance actually contributes to trust, or whether it is merely a nice-to-have.
To answer this question, the researchers studied two real-world data science projects, both in the asset management domain but with very different outcomes. The first project, which we can call Project A, was run by a large European public organization responsible for maintaining national highways. The goal was to predict asphalt life expectancy so that maintenance could be performed just‑in‑time, avoiding both premature repairs and dangerous delays. The organization had already implemented a mature data governance framework: clear data owners, a data quality framework with eight dimensions and forty‑seven subdimensions, automatic auditing tools, and a strict annual planning cycle. Managers were even required to know the monetary cost of producing each dataset. When the data science team built a model using over forty datasets including weather, traffic, and IoT sensor data the outcomes were not only technically superior to traditional methods; they were also fully accepted and integrated into business processes. As one interviewee put it, the improved predictions “enabled better maintenance planning, which has significantly reduced premature maintenance, improving road safety and cost savings” (Interviewee 1, Project A, as cited in Brous & Janssen, 2020, p. 9).
The second project, Project B, could hardly have been more different. This project aimed to detect fraudulent electricity usage in medium‑ and low‑voltage grids without infringing on personal privacy. The organization a European distribution grid operator had only an initial, immature data governance capability. There were no clear data owners. Metadata was missing. A subsidiary that supplied critical data was sold during the project, leaving no one with definitive knowledge of how the data had been collected. Data engineers changed code without consulting data scientists. Despite all this, the team eventually built a model that greatly outperformed the existing commercial off‑the‑shelf system. Yet when they presented their results to the business, the model was rejected. The data scientists reported that the business leaders “didn’t want to believe the results. [The organization] has spent millions on the COTS system, and they are reluctant to accept that they’ve made a procurement error” (Data Scientist, Project B, as cited in Brous & Janssen, 2020, p. 11). The data, they argued, was unreliable but ironically, it was the same data that fed the incumbent system.
What explains this stark difference? Brous and Janssen argue that data governance acts as a boundary condition for trustworthy data science. A boundary condition, in their definition, is a socio‑technical constraint that must be satisfied before you can trust a data science outcome (Busse et al., 2017). In other words, no matter how sophisticated your algorithm, if you have not governed your data properly if you do not know who owns each dataset, if quality is not measured, if privacy compliance is not enforced then decision‑makers will, quite rationally, withhold their trust.
The authors ground their analysis in duality of technology theory (Orlikowski, 1992), which sees technology as both a product of human action and a medium for further action. From this perspective, data science is not a purely rational, external force. It is shaped by the people who build it, by the organizational structures around it, and by the governance mechanisms that coordinate and control it. This is why the four propositions that the study tested all found strong support: organizations with established data governance are more likely to have a well‑functioning data science capability, to generate trusted outcomes, to meet the necessary organizational conditions (such as clear roles and resources), and to manage the changes that data science inevitably introduces.
The practical implication is profound. Many organizations rush to hire data scientists and buy the latest machine learning tools, only to wonder why the business refuses to adopt the results. Brous and Janssen (2020) suggest that this order is backwards. Managers should first ensure that data governance is mature that data owners are appointed, quality frameworks are in place, compliance is monitored, and there is a regular cycle of planning and control. Only then should they focus on building the data science capability. Simply “throwing data” at a problem, as the authors memorably write, without regard for the quality or bias of the data or the algorithm itself, does not necessarily lead to acceptance of the decision outcomes.
Of course, the research has limitations. It examined only two projects, both in (semi)‑government organizations and within the asset management domain, which is naturally data‑rich. Less data‑intensive domains might face different challenges. Nevertheless, the core insight that trust in data science is not a purely technical problem but a socio‑technical one, tightly coupled with governance has proven influential. It calls for a shift in mindset: from asking “how accurate is our model?” to asking “how trustworthy is our data ecosystem?”
In the end, the difference between Project A and Project B was not the skill of the data scientists or the sophistication of the algorithms. Both teams delivered technically excellent models. The difference was governance. And that is a lesson that any organization serious about data‑driven decision‑making cannot afford to ignore.
References
Al-Ruithe, M., Benkhelifa, E., & Hameed, K. (2019). A systematic literature review of data governance and cloud data governance. Personal and Ubiquitous Computing, 23, 839-859. https://doi.org/10.1007/s00779-017-1104-3
Brous, P., & Janssen, M. (2020). Data governance as a boundary condition for data science decision-making outcomes. Administrative Sciences, 10(4), 81. https://doi.org/10.3390/admsci10040081
Brous, P., Janssen, M., Schraven, D., Spiegeler, J., & Duzgun, B. C. (2017). Factors influencing adoption of IoT for data-driven decision making in asset management organizations. In Proceedings of the 2nd International Conference on Internet of Things, Big Data and Security (IoTBDS 2017) (pp. 70-79). SciTePress.
Busse, C., Kach, A. P., & Wagner, S. M. (2017). Boundary conditions: What they are, how to explore them, why we need them, and when to consider them. Organizational Research Methods, 20(4), 574-609. https://doi.org/10.1177/1094428116641191
DAMA International. (2017). DAMA-DMBOK: Data management body of knowledge (2nd ed.). Technics Publications.
Orlikowski, W. J. (1992). The duality of technology: Rethinking the concept of technology in organizations. Organization Science, 3(3), 398-427. https://doi.org/10.1287/orsc.3.3.398
van den Broek, T., & van Veenstra, A. F. (2018). Governance of big data collaborations: How to balance regulatory compliance and disruptive innovation. Technological Forecasting and Social Change, 129, 330-338. https://doi.org/10.1016/j.techfore.2017.09.040





: Tantangan dan Peluang di Indonesia")
